本文最后更新于194 天前,其中的信息可能已经过时,如有错误请发送邮件到big_fw@foxmail.com
--IO线程异常
IO线程状态显示为:connecting
reset slave all; 把master配置清除。之前连接主库配置信息
show slave status\G 查看配置信息,不加; 不然报错
show variables like '%max_connect%'; 查看连接用户设置
select * from slave_master_info\G 查看配置同步信息
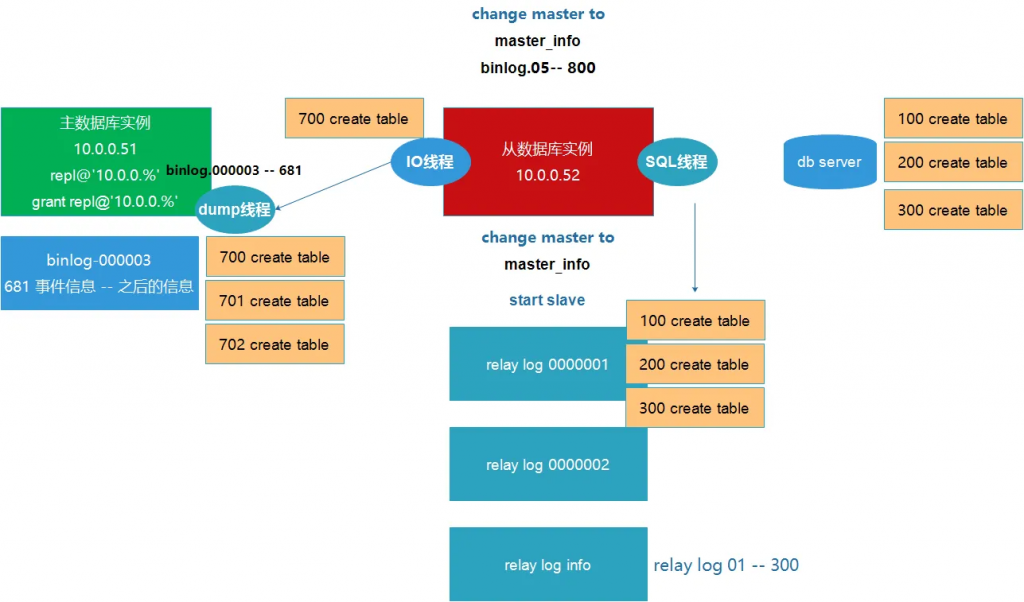
show relaylog events in 'db02-relay-bonxxx'; 命令行ll /data/3306/data
cd /data/3306/data mysqlbinlog db02-relay-bonxxx
1)- 连接地址、端口、用户、密码信息不对可能会导致连接异常;
从库调整连接信息
stop slave; 关闭同步 ,日志信息也会自动清理
reset slave all; -- 之前连接主库配置信息清除
change master to .. -- 重新和主库建立连接
start slave;
清除配置信息,重新加载,要先停止,再清除,最后录入配置信息,开启同步
测试;
51主库
vim /etc/my.cnf 修改[mysql]里端口号port=3306 改为3307
/etc/init.d/mysql.server restart
netstat -lntup|grep mysql 3307
52从库
mysql
stop slave;
start slave; 让主库信息生效
show slave status\G 显示Slave_IO_Running:connecting
Last_IO_Errno: 2003 错误编码
Last_IO_Error: xxx 这里是错误信息
恢复方法:主库修改回3306端口 并重启 从库清除连接配置,再次配置同步信息连接
或者从库修改,除连接配置,再次配置同步信息连接,注意配置信息里端口修改为先在主库端口3307
PS:清理主从配置或关闭主从同步前,需要确认好主从同步的位置点
2)- 防火墙安全策略阻止连接建立、网络通讯配置异常影响连接建立;
从库上 ping 主库不通 telnet 主库端口 超时 --- 找网络人员排查问题
3)- 到达数据库服务连接数上限,造成主从连接产生异常;
show variables like '%max_connect%'
max_connections -- 设置数据库最大连接数(默认 151 建议范围不要超过1500-3000)
set global max_connections=3 可以设置
测试
set global max_connections=3
quit
show variables like '%max_connect%' 退出生效 查看
show processlist; 查看有几个连接信息 第一行even_scheduler不算在内
复制多个窗口 mysql -uroot -kp1 多次连接
发现root连接可以加上原有的repl用户,一共连接四个,第五个连接失败,设置为3次的情况
若通repl用户,只能3次,原因是root用户默认可以多连接一次,以解决管理多余用户,使其他用户可以连接
解决方法: 一 主库设置连接上限增加 二,主库中show processlist 然后kill id号 关闭多余用户连接让从库有位置连接
腾出位置 从库就可以自动连接成功
IO线程状态显示为:no
1)-IO线程在请求日志信息失败,有可能日志信息被无意清理了 (binlog清理 relay log清理-重新生成)
/data/3306/log 下有日志信息被清理或移动
测试
主库尽量不要动日志文件
从库模拟
show slave status\G 记录好binlog日志master_log_file read_master_log_pos
cd /data/3306/log
stop slave;
reset slave all;
配置信息 日志编写超过上边记录的日志号,start slave; 启动后show slave status\G查看
发现Slave_IO_Running:No 若主库/data/3306/log 中bin-log-index被删除也会报错
2)-IO线程在请求日志信息失败,有可能是主从配置的标识信息重复冲突了(server_id server_uuid)
server_id 一般默认为1 主从机子需要区分,一致会报错,从库/etc/my.cnf要指定
server_uuid /data/3306/data/ 目录下有 cat auto.cnf 文件,有server_uuid 编号
一般默认是随机生成,若一样会报错
--SQL线程异常
SQL线程状态显示为:no 出现异常只有no报错
可能导致异常原因:(从库数据或设置异常导致)
1)-回放的对象已经存在,涉及到的对象可能有库,表,用户,索引...; (DDL操作冲突)
主从状态正常下 从库先创建一个库,t2,然后主库也创建一个库t2,名字重复 然后从库检查
Slave_SQL_Running:No 报错
2)-插入(insert) 的操作对象有异常,修改(update alter)的操作对象有异常,删除(delete drop)的
操作对象有异常(DML操作冲突 --约束信息)
一般约束信息造成,比如号码不能相同等,主从库都输入一样号码就报错
3)-由于数据库设置的约束信息,与执行的SQL语句产生冲突问题
4)- 在数据库不同版本之间进行数据同步时,可能出现配置冲突问题(比如:5.6可以识别时间为0字段,5.7不能识别时间为0字段)
PS:当SQL线程进行回放数据(执行relaylog中SQL语句时),不能执行成功
可能造成异常情况:
- 在进行主从配置时,指定的位置点出现错误(change master to);
- 在进行主从配置前,从库被写入相应的数据信息了,与主库同步数据产生冲突(误连接从库进行操作了);
避免管理人员连接数据库出错,可以将从库设置为只读状态
read_only=ON
super_read_only=ON
- 在从库工作繁忙状态时,从库宕机了,业务恢复后可能出现异步同步数据错乱(主库操作创建表操作没同步,同步了插入表操作);
避免异步方式同步数据错误,可以调整主从同步方式为 半同步 增强半同步 全同步
- 在进行主从切换时(假设进行的是手工切换),没有正确操作锁定源主库和binlog日志信息;(画图说明)
导致切换前主库数据没有完全同步,切换后从库数据(原主库)比主库数据(原从库)信息更全;
- 在应用数据库双主结构时,没有正确使用(经常导致相互同步数据,主键或唯一键冲突)(画图说明)
若企业创建必须使用双主架构,实现双写机制,可以使用全局序列机制,实现主键或唯一键的统一分配;
--SQL线程出现no,如何解决问题
方式一;将从库冲突对象或数据删除
比如主从创建库名重复冲突 删除从库重复库,就会自动同步到从库相同库,这样不报错
drop 对象 delete数据
方式二:跳过数据冲突的错误信息
比如上边主从创建库名冲突,其实不报错也没事,跟同步一样结果,主从都会有同名库,跳过没事
set global sql_slave_skip_counte=2; --实现设置跳过冲突事务的次数信息
1007 错误码 表示数据库主从同步冲突
1050 错误码 表示数据表主从同步冲突
1062 错误码 表示数据信息主从同步冲突
vim /etc/my.cnf 永久设置
slave_skip_errors='1007,1050,1062'; --实现设置忽略指定错误码信息
/etc/init.d/mysql.server restart
mysql
select @@slave_skip_errors;
---确认主从是否延迟同步(原因/避免)
1)-网络通讯不稳定,有带宽阻塞等情况,造成主从数据传输同步延时
2)-主从硬件差异大,从库磁盘性能较低,内存和CPU资源都不够充足
3)-主从配置区别大,从库配置没有优化,导致并发出口能力低于主库
---主库因素导致的延时问题
1)主要涉及Dump thread工作效率缓慢,可能是由于主库并发压力比较大
2)主要涉及Dump thread工作效率缓慢,可能是由于从库数量比较多导致 (1-3从 1-4从 一主N从)
3)主要涉及Dump thread工作效率缓慢,主要由于线程本身串型工作方式(利用组提交缓 解此 类问题-5.6开始 group commit)
#主库查看是否开启组提交
binlog_group_commit_synv_delay --半同步主从构建时,会应用
--表示延迟多少微妙同步到磁盘
binlog_group_commit_synv_no_delay_count
--表示延迟提交的最大事务数量
主库本身可以并发多个事务运行,默认情况下主从同步Dump thread只有一个,只能采用串型方式传输事务日志信息
---从库因素导致的延时问题
1)-从库产生延迟受SQL线程影响较大,由于线程本身串型工作方式导致
利用不同数据库并执行事务操作,但是一个库有多张表情况,产生大量并发事务操作,依旧是串型的(5.6开始 多SQL线程回放)
利用logical-clock机制进行并发回收,由于组提交事务是没有冲突的,从库并行执行也不会产生冲突(5.7开始 多SQL线程回放)
根据日志内容信息,获取ligical_clock机制的组提交标记信息
# 从库开启逻辑时钟功能,并设置SQL多线程回放
slave_parallel_type=loglcal_clock
-- 设置回放方式为loglcal_clock
slave_parallel_workers=8
-- 设置SQL回放数据线程数量
其他因素导致的延时问题:
- 由于数据库大事务产生的数据同步延时问题;(更新100W数据/尽量切割事务)
- 由于数据库锁冲突机制的数据同步延时问题;(资源被锁无法同步/隔离级别配置RR-锁冲突严重,可调整RC降低延时 索引主从一致)
- 由于数据库过度追求安全配置也会导致同步延时问题(从库关闭双一参数);