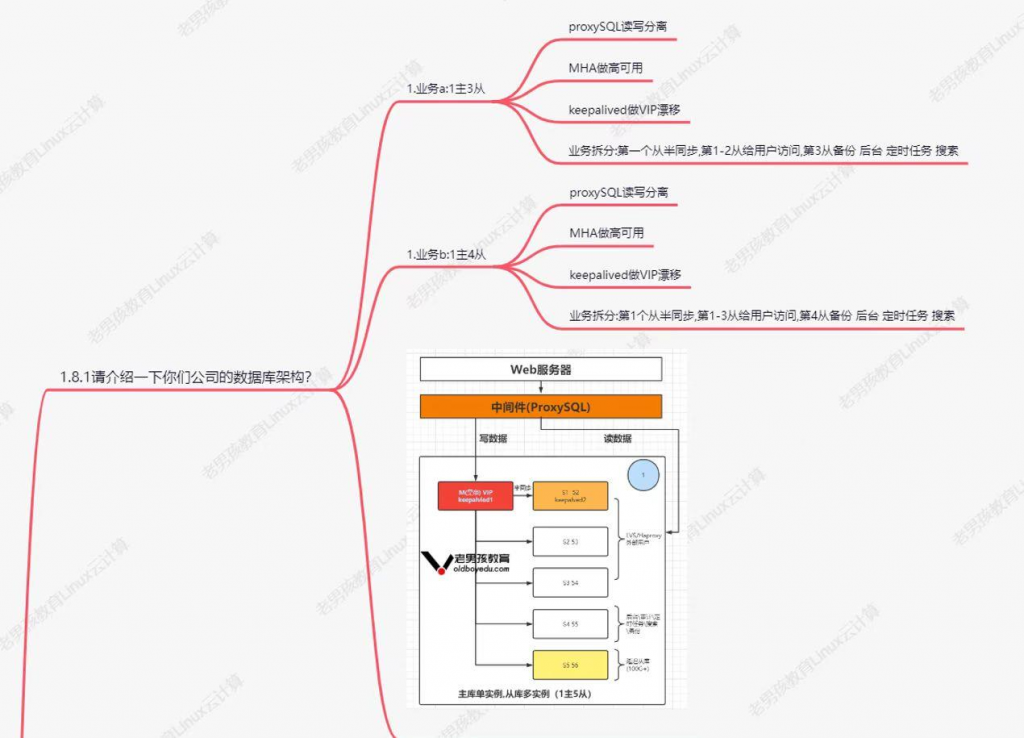
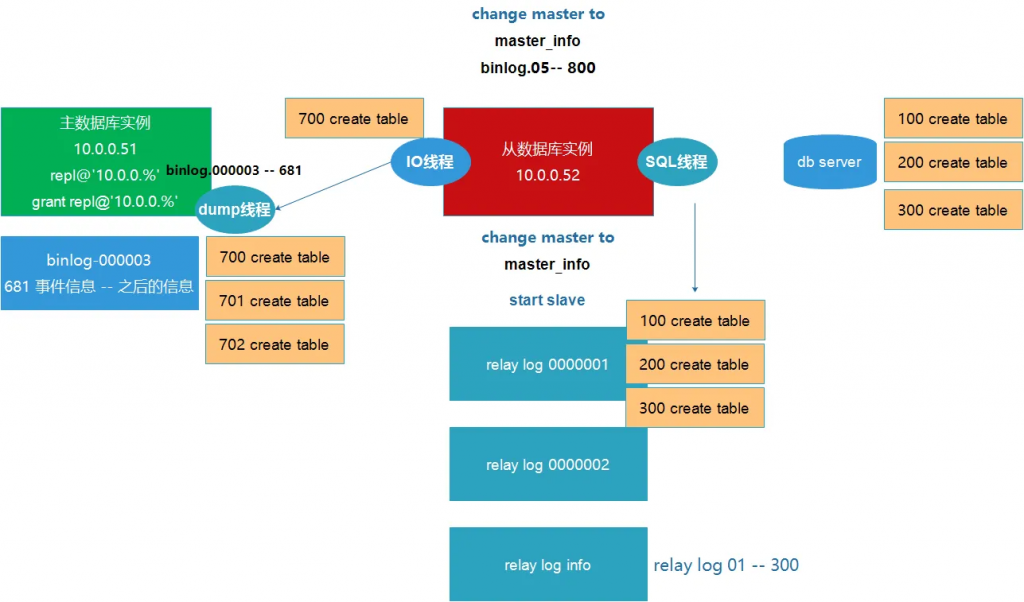
本文最后更新于194 天前,其中的信息可能已经过时,如有错误请发送邮件到big_fw@foxmail.com
工作原理: 01:通过 masterha_manger 启动 MHA
02:监控;manager 自动调用 masterha_master_monitor 脚本,监测主库心跳,最多 4 次机会,如果都没有心跳,主机宕机
03:选主 alive 数组:所有节点 lastest 数组:最接近主库日志量的节点 pref 数组:设置了 candidate_master>0 节点(candidate_master 大于 0 表示该节点有可能选做为备选节点) bad 数组:不适合做主库节点(没开 binlog,日志差异太大,设定了 no_master)
04:数据补偿 01:如果 ssh 能连接到主库,则调用 save_binary_logs 脚本,立即保存缺失部分 binlog,scp 到各个从库进行恢复。 02:如果 ssh 连接不上主库,则通过 apply_diff_relay_logs 脚本计算从库之间的日志差异,并进行恢复 03:冗余方案,binlogserver 功能,远程拉取日志
05:主从身份切换
06:vip 漂移(调用脚本 master_ip_failover)
07:告警(脚本: send_report)